Job Sequencing Problem with Integer Lengths#
Here we show how to solve the job sequencing problems with integer lengths using OpenJij, JijModeling, and JijModeling Transpiler. This problem is also mentioned in 6.3. Job Sequencing with Integer Lengths in Lucas, 2014, “Ising formulations of many NP problems”.
Overview of the Job Sequencing Problem with Integer Lengths#
We consider several computers and tasks with integer lengths (i.e., task 1 takes one hour to execute on a computer, task 2 takes three hours, and so on). When allocating these tasks to multiple computers to execute, the question is what combinations can be used to distribute the execution time of the computers without creating bias. We can obtain a leveled solution by minimizing the largest value.
Example#
As an example of this problem, consider the following situation.
Here are 10 tasks and 3 computers. The length of each of the 10 tasks is 1, 2, …, 10. Our goal is to assign these tasks to the computers and minimize the maximum amount of time the tasks take. In this case, one of the optimal solution is and , whose maximum execution time of computers is 19.
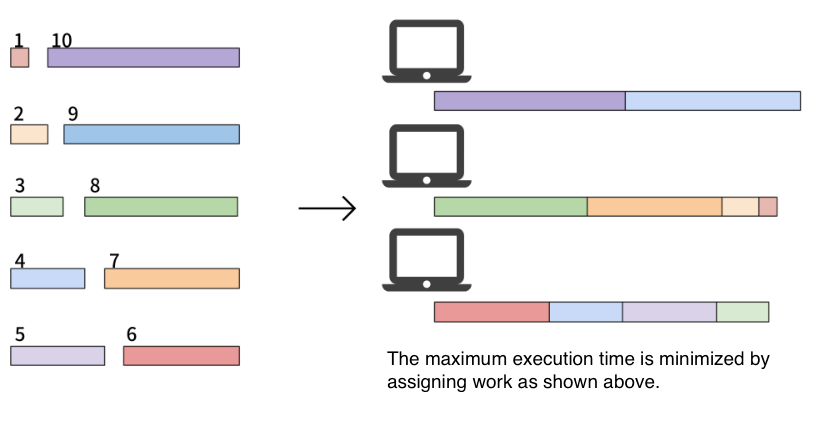
Mathematical Model#
Next, we introduce tasks and list of the execution time . Given computers, the total execution time of the th computer to perform its assigned tasks is where is a set of assigned tasks to the th computer. Note that . Finally, let us denote to be a binary variable which is 1 if the th task is assigned to the th computer, and 0 otherwise.
Constraint#
Each task must be performed on one computer; for example, task 3 is not allowed to be executed on both computers 1 and 2. Also, it is not allowed that there is no computer that handles task 3.
Objective Function#
We consider the execution time of the th computer as the reference and minimize the difference between that and others. This reduces the execution time variability and the tasks are distributed equally.
Modeling by JijModeling#
Next, we show an implementation using JijModeling. We first define variables for the mathematical model described above.
import jijmodeling as jm
# defin variables
L = jm.Placeholder('L', dim=1)
N = L.shape[0].set_latex('N')
M = jm.Placeholder('M')
x = jm.Binary('x', shape=(N, M))
i = jm.Element('i', (0, N))
j = jm.Element('j', (0, M))
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[1], line 1
----> 1 import jijmodeling as jm
4 # defin variables
5 L = jm.Placeholder('L', dim=1)
ModuleNotFoundError: No module named 'jijmodeling'
L is a one-dimensional array representing the execution time of each task.
N denotes the number of tasks, and M is the number of computers.
We define a two-dimensional binary variables x, and we set the subscripts i and j used in the mathematical model.
Constraint#
We implement the constraint in equation (1) as follows:
# set problem
problem = jm.Problem('Integer Jobs')
# set constraint: job must be executed using a certain node
problem += jm.Constraint('onehot', x[i, :]==1, forall=i)
x[v, :] implements Sum(n, x[v, n]) in a concise way.
Objective Function#
Let us implement the objective function of equation (2).
Sum((j, j!=0), ...) denotes taking the sum of all cases where j is not 0.
# set objective function: minimize difference between node 0 and others
A_0 = jm.Sum(i, L[i]*x[i, 0])
A_j = jm.Sum(i, L[i]*x[i, j])
problem += jm.Sum((j, j!=0), (A_0 - A_j) ** 2)
problem
Instance#
Here we set the execution time of each job and the number of computers. We use the same values from the example mentioned.
# set a list of jobs
inst_L = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# set the number of Nodes
inst_M = 3
instance_data = {'L': inst_L, 'M': inst_M}
Undefined Multiplier#
This problem has one constraint, and we need to set the weight of that constraint.
We will set it to match the name we gave in the Constraint part earlier using a dictionary type.
# set multipliers
lam1 = 1.0
multipliers = {'onehot': lam1}
Conversion to PyQUBO by JijModeling Transpiler#
JijModeling has executed all the implementations so far. By converting this to PyQUBO, it is possible to perform combinatorial optimization calculations using OpenJij and other solvers.
from jijmodeling.transpiler.pyqubo import to_pyqubo
# convert to pyqubo
pyq_model, pyq_chache = to_pyqubo(problem, instance_data, {})
qubo, bias = pyq_model.compile().to_qubo(feed_dict=multipliers)
The PyQUBO model is created by to_pyqubo with the problem created by JijModeling and the instance_data we set to a value as arguments.
Next, we compile it into a QUBO model that can be computed by OpenJij or other solver.
Optimization by OpenJij#
This time, we will use OpenJij’s simulated annealing to solve the optimization problem.
We set the SASampler and input the QUBO into that sampler to get the result of the calculation.
import openjij as oj
# set sampler
sampler = oj.SASampler(num_reads=100)
# solve problem
response = sampler.sample_qubo(qubo)
Decoding and Displaying the Solution#
Decode the returned results to facilitate analysis.
# decode solution
result = pyq_chache.decode(response)
From the results thus obtained, we can see how the task execution is distributed.
import matplotlib.pyplot as plt
import numpy as np
# extract feasible solution
feasibles = result.feasible()
# get the index of the lowest objective function
objectives = np.array(feasibles.evaluation.objective)
lowest_index = np.argmin(objectives)
# get indices of x = 1
indices, _, _ = feasibles.record.solution['x'][lowest_index]
# get task number and execution node
tasks, nodes = indices
# get instance information
L = instance_data['L']
M = instance_data['M']
# initialize execution time
exec_time = np.zeros(M, dtype=np.int64)
# compute summation of execution time each nodes
for i, j in zip(tasks, nodes):
plt.barh(j, L[i], left=exec_time[j],ec="k", linewidth=1,alpha=0.8)
plt.text(exec_time[j] + L[i] / 2.0 - 0.25 ,j-0.05, str(i+1),fontsize=12)
exec_time[j] += L[i]
plt.yticks(range(M))
plt.ylabel('Computer numbers')
plt.xlabel('Execution time')
plt.show()
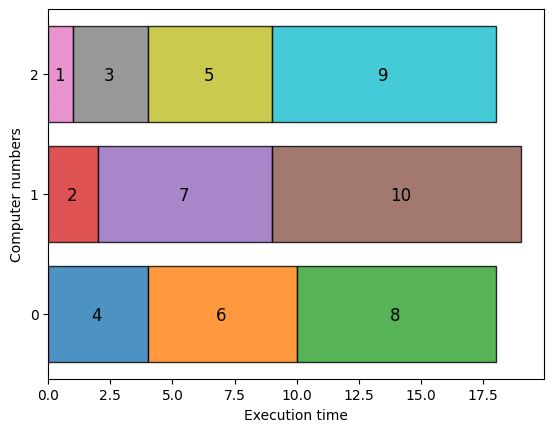
With the above visualization, we obtain a graph where the execution times of three computers are approximately equal. The maximum value is 19, as explained at the beginning.