1-OpenJij 入門¶
![]()
インストールにはpipを使用します。ただし、numpy を事前にインストールしておいてください。
[ ]:
!pip install openjij
[ ]:
# 以下のコマンドでOpenJijの情報を見ることができます。実行環境によって出力は異なります。
!pip show openjij
Ising model¶
Ising model は統計物理学で扱われるモデルで、以下のように書かれます。
\(\sigma_i\)は物理ではスピンという物理量に対応するため、スピン変数もしくは単純にスピンと呼ばれることもあります。スピンとは小さな磁石のようなものです。-1 が磁石が上向き、1が下向きのように変数の値と物理(磁石の向き)が対応します。
OpenJijは\(J_{ij} と h_i\)が与えられたときに\(H(\{\sigma_i\})\)を最小化するスピン変数の組み\(\{\sigma_i\}\)を探してくれる数値計算ライブラリです。
具体的な例を一つ見ましょう。
OpenJijに問題を投げてみる¶
変数の数が\(N=5\)で縦磁場と相互作用が
ではこれを再現することをOpenJijを用いて計算しましょう。
[4]:
import openjij as oj
# 問題を表す縦磁場と相互作用を作ります。OpenJijでは辞書型で問題を受け付けます。
N = 5
h = {i: -1 for i in range(N)}
J = {(i, j): -1 for i in range(N) for j in range(i+1, N)}
print('h_i: ', h)
print('Jij: ', J)
h_i: {0: -1, 1: -1, 2: -1, 3: -1, 4: -1}
Jij: {(0, 1): -1, (0, 2): -1, (0, 3): -1, (0, 4): -1, (1, 2): -1, (1, 3): -1, (1, 4): -1, (2, 3): -1, (2, 4): -1, (3, 4): -1}
[5]:
# まず問題を解いてくれるSamplerのインスタンスを作ります。
# このインスタンスの選択で問題を解くアルゴリズムを選択できます。
sampler = oj.SASampler(num_reads=1)
# samplerのメソッドに問題(h, J)を投げて問題を解きます。
response = sampler.sample_ising(h, J)
# 計算した結果(状態)は response.states に入っています。
print(response.states)
# もしくは添字付きでみるには samples関数 を用います。
print([s for s in response.samples()])
[[1 1 1 1 1]]
[{0: 1, 1: 1, 2: 1, 3: 1, 4: 1}]
また、巨大な問題を扱う際にはnumpyを用いた入力が便利となります。以下の数式の形式で入力が可能です。
[2]:
#!pip install numpy -U
[9]:
import numpy as np
mat = np.array([[-1,-0.5,-0.5,-0.5],[-0.5,-1,-0.5,-0.5],[-0.5,-0.5,-1,-0.5],[-0.5,-0.5,-0.5,-1]])
print(mat)
# oj.BinaryQuadraticModelを作成し、変数タイプ (vartype)を'SPIN'にします。
bqm = oj.BinaryQuadraticModel.from_numpy_matrix(mat, vartype='SPIN')
# 各要素をprintで確認できます。J_{ij}とJ_{ji}は内部でまとめられます。
print(bqm)
sampler = oj.SASampler(num_reads=1)
response = sampler.sample(bqm)
print(response.states)
[[-1. -0.5 -0.5 -0.5]
[-0.5 -1. -0.5 -0.5]
[-0.5 -0.5 -1. -0.5]
[-0.5 -0.5 -0.5 -1. ]]
BinaryQuadraticModel({3: -1.0, 2: -1.0, 1: -1.0, 0: -1.0}, {(1, 2): -1.0, (2, 3): -1.0, (1, 3): -1.0, (0, 3): -1.0, (0, 2): -1.0, (0, 1): -1.0}, 0.0, Vartype.SPIN, sparse=False)
[[1 1 1 1]]
OpenJijの解説¶
もう一つのインターフェースについてはここでは解説しませんが、OpenJijの仕組み
graph, method, algorithmを直接使うことで拡張のしやすさを備えています。ここでは上のセルで扱ったインターフェースを使えるようになれば十分でしょう。
Sampler¶
先ほどは問題を辞書型で作ったあとに、Samplerのインスタンスを作りました。
sampler = oj.SASampler(num_reads=1)
ここでこのSamplerというのがどのようなアルゴリズム、マシンを使うかを選択しています。他のアルゴリズムを試したい時はこのSamplerを変更します。またnum_reads引数に整数を入れることで、一度に解く回数(iteration回数)を指定することができます(詳細は後述)。
OpenJijで扱っているアルゴリズムはヒューリスティックな確率アルゴリズムです。問題を解くたびに返す解が違ったり、必ずしも最適解を得ることができません。 よって複数回問題を解き、その中でよい解を探すという手法をとります。そのため、ここでは解をサンプリングするという気持ちを込めてSamplerと呼んでいます。
num_readsの値を明記しない場合、デフォルトのnum_reads=1で実行されます。
SASamplerはSimulated Annealingというアルゴリズムを用いて、解をサンプリングしてくるSamplerです。SQASampler : Simulated Quantum Annealing(SQA) という量子アニーリングを古典コンピュータでシミュレーションするアルゴリズム
GPUSQASampler : SQAをGPUで実行するSamplerです。Chimeraグラフという特殊な構造のみが現状扱える
のSamplerが用意されています。
sample_ising(h, J)¶
上述のとおり、問題を解く際は.sample_ising(h, J)のように縦磁場と相互作用を変数として代入して投入します。
後述しますた、Isingモデルと等価なQUBOの最適化を行う時は.sample_qubo(Q)を用います。
Response¶
.sample_ising(h, J)はResponseクラスを返します。ResponseクラスにはSamplerが解いて出てきた解と各解のエネルギーが入っています。
.states :
type : list(list(int))
num_reads回数の解が格納されている > 物理ではスピンの配列(解)を状態と呼ぶことがあります。.statesにはnum_reads回だけ解いた解が格納されているので複数の状態を格納しているという気持ちを込めて .states としています。
.energies:
type : list(float)
num_reads回数分の各解のエネルギーが格納されている
.indices:
type: list(object)
解がlistでstatesに入っているが、それに対応する各スピンの添字を格納されている
.first.sample:
type: dict
最小エネルギー状態を取るときの状態が格納されている
.first.energy:
type: float
最小エネルギーの値
ResponseクラスはD-WaveのdimodのSampleSetクラスを継承しています。より詳細な情報は以下のリンクに記述されています。
というパラメータが参照できます。実際にコードを見てみましょう。
[4]:
# 実は h, J の添字を示す、辞書のkeyは数値以外も扱うことができます。
h = {'a': -1, 'b': -1}
J = {('a', 'b'): -1, ('b', 'c'): 1}
# num_reads 引数に値を代入することで、SAを10回試行する計算を一度の命令で解くことができます。
sampler = oj.SASampler(num_reads=10)
response = sampler.sample_ising(h, J)
print(response.first.sample)
print(response.first.energy)
{'a': 1, 'b': 1, 'c': -1}
-4.0
[5]:
# response.states を見てみましょう。10回分の解が入っていることがわかります。
print(response.states)
[[ 1 1 -1]
[ 1 1 -1]
[ 1 1 -1]
[ 1 1 -1]
[ 1 1 -1]
[ 1 1 -1]
[ 1 1 -1]
[ 1 1 -1]
[ 1 1 -1]
[ 1 1 -1]]
num_reads などコンストラクタで渡すパラメータは
.sample_isingなどのサンプリングを実行するメソッドで上書きすることができます。response = sampler.sample_ising(h, J, num_reads=2) response.states > [[1, 1, -1],[1, 1, -1]]
今回は問題が簡単なので、10回とも同じ答え [1,1,-1] になっていることがわかります。
[6]:
# 次にエネルギーを見てみましょう。
response.energies
[6]:
array([-4., -4., -4., -4., -4., -4., -4., -4., -4., -4.])
response.statesに入っている解はリストになっているため、問題をセットした時の a, b, cという文字列との対応がわかりません。それを調べるためにresponse.variablesを見てみましょう。[7]:
response.variables
[7]:
Variables(['a', 'b', 'c'])
最小のエネルギー値を持った状態のみが知りたい場合には .first が便利です。
[8]:
response.first
[8]:
Sample(sample={'a': 1, 'b': 1, 'c': -1}, energy=-4.0, num_occurrences=1)
QUBOを解いてみる¶
社会の実問題を解きたい場合には、Ising modelよりも QUBO(Quadratic unconstraited binary optimization)として定式化した方が素直な場合が多いです。基本的には上述のIsing modelを使って解いた場合と同じです。
QUBOは以下のように書かれます。
Ising modelとの違いは、2値変数が0 と 1のバイナリ変数であることです。\(\sum, Q_{ij}\)の取り方には他にもやり方(例えば\(Q_{ij}\)を対称行列にするなど)がありますが、今回は上式のように定式化しておきましょう。
Ising モデル と QUBO は相互変換が可能という意味で等価です。 \(q_i = (\sigma_i + 1)/2\)という変換式を用いることで、変換が可能です。
QUBOでは\(Q_{ij}\)が与える問題で、\(H(\{q_i\})\)を最小化する0, 1の組み合わせ\(\{q_i\}\)を探しましょうという問題になります。ほぼIsing modelと一緒です。
また\(q_i\)はバイナリ変数なので、\(q_i^2 = q_i\)であることがわかります。よって上式を以下のように書き分けることができます。
\(Q_{ij}\)の添字が同じところは \(q_i\)の1次の項の係数に対応します。
これをOpenJijで解いてみましょう。
[9]:
# Q_ij を辞書型でつくります。
Q = {(0, 0): -1, (0, 1): -1, (1, 2): 1, (2, 2): 1}
sampler = oj.SASampler()
# QUBOを解く時は .sample_qubo を使います。
response = sampler.sample_qubo(Q)
print(response.states)
[[1 1 0]]
少し難しい問題を解いてみる¶
これまで解いてきた問題は簡単すぎたので、少し難しい問題を解いてみましょう。
今度は変数の数が50個でランダムに\(Q_{ij}\)が振られたQUBOを解いてみたいと思います。
[10]:
N = 50
# ランダムにQij を作る
import random
Q = {(i, j): random.uniform(-1, 1) for i in range(N) for j in range(i+1, N)}
# OpenJijで解く
sampler = oj.SASampler()
response = sampler.sample_qubo(Q, num_reads=100)
[11]:
# エネルギーを少しみてみます。
response.energies[:5]
[11]:
array([-60.31847329, -60.31847329, -60.31847329, -60.31847329,
-60.50688986])
[12]:
import matplotlib.pyplot as plt
plt.hist(response.energies, bins=15)
plt.xlabel('Energy', fontsize=15)
plt.ylabel('Frequency', fontsize=15)
plt.show()
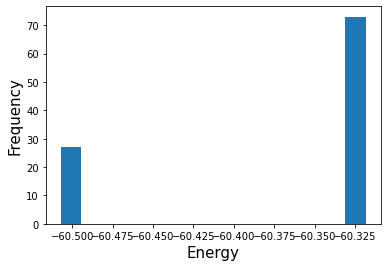
エネルギーが低いほど良い状態を算出したことになりますが、稀にエネルギーが高い状態も算出されていることが上のヒストグラムからわかります。しかし大半の計算結果はエネルギーが最低の状態を算出しています。 解いた(サンプルした)状態のうち一番低い解が最適解に近いはずなので、その解を.statesから探しましょう。 > 注意: SAは必ずしも最適解を導くものではありません。よってエネルギーが一番低い解を選んでも最適解であるという保証はありません。あくまで近似解です。
[13]:
import numpy as np
min_samples = response.first
min_samples
[13]:
Sample(sample={0: 0, 1: 0, 2: 1, 3: 1, 4: 1, 5: 1, 6: 1, 7: 0, 8: 1, 9: 0, 10: 1, 11: 1, 12: 0, 13: 0, 14: 0, 15: 0, 16: 1, 17: 0, 18: 0, 19: 1, 20: 1, 21: 0, 22: 1, 23: 1, 24: 1, 25: 1, 26: 0, 27: 0, 28: 1, 29: 1, 30: 1, 31: 1, 32: 1, 33: 1, 34: 1, 35: 1, 36: 1, 37: 0, 38: 0, 39: 0, 40: 1, 41: 1, 42: 1, 43: 1, 44: 1, 45: 0, 46: 0, 47: 0, 48: 0, 49: 1}, energy=-60.506889856831975, num_occurrences=1)
これでエネルギーが最も低い解を得ることができました。この.firstに入っている状態が、今回得られた近似解です。これで「問題を近似的に解いた」ということになります。
num_occurrencesは計算の結果その状態が何回出力されたかを表しています。
次回は “2-Evaluation” で Time to Solution や残留エネルギーなど、解をはかる指標について説明します。